Calfa OCR/HTR: Output Formats
You have to choose the output format of the OCR before to start processing. Select the best format to match the objectives of your project.
Raw text
Text is recognized and saved raw without any other element, in an editable text file. Line breaks are kept.
Available formats : TXT DOCX ODT PDFԱՆԱՀԻՏ
իգրանի որդի Արտաւազդ Գ
ան Հայկազն Տիգրան Ա.ի մը նուիրուած դիւցազներգական գլուխները
...
Ordered data
Page layout is analyzed. Layout elements such as titles, subtitles, author names, captions, footnotes or margin notes are detected and tagged. These tags are included in the data structure.
Available formats : XML JSON pageXML ALTO
<title>ԱՆԱՀԻՏ</title>
<subtitle>Տիգրանի որդի Արտաւազդ Գ</subtitle>
<body>ան Հայկազն Տիգրան Ա.ի մը նուիրուած դիւցազներգական գլուխները ...
Spatial data
Page layout is analyzed: lines and text regions are located. The exact position in the page of every element is saved with the corresponding recognized text. PageXML or ALTO formats compile the text associated with coordinates, allowing the text to be displayed in the page. These inter-operable formats are usable with various data visualisation tools and databases.
Available formats : pageXML ALTO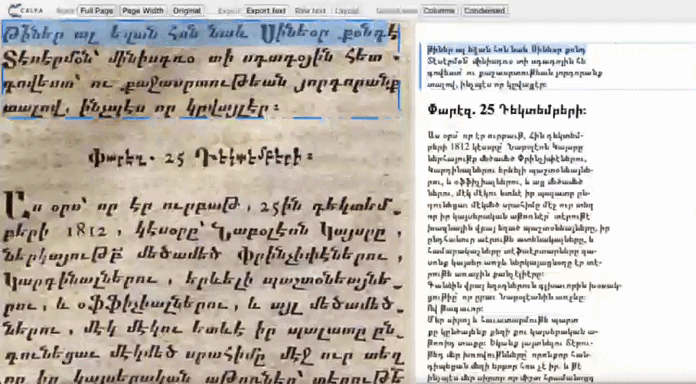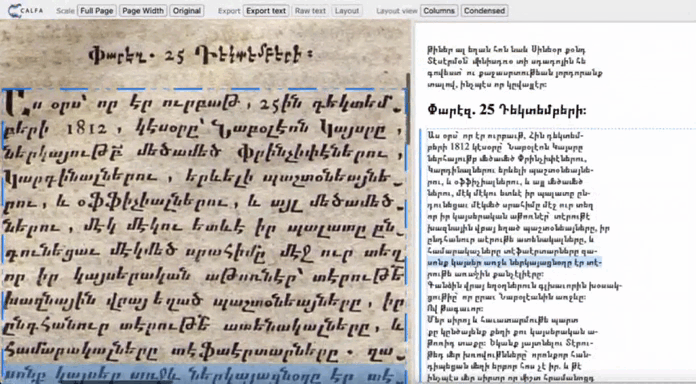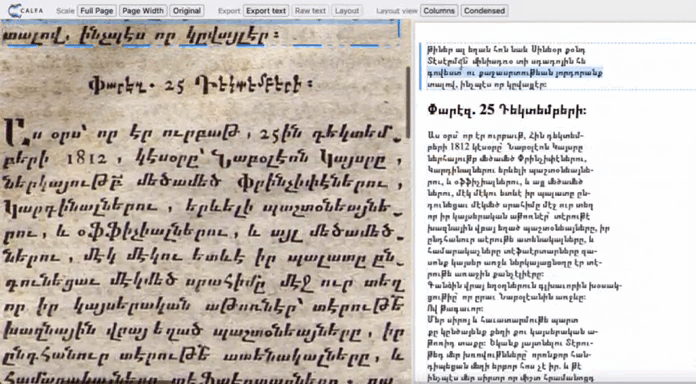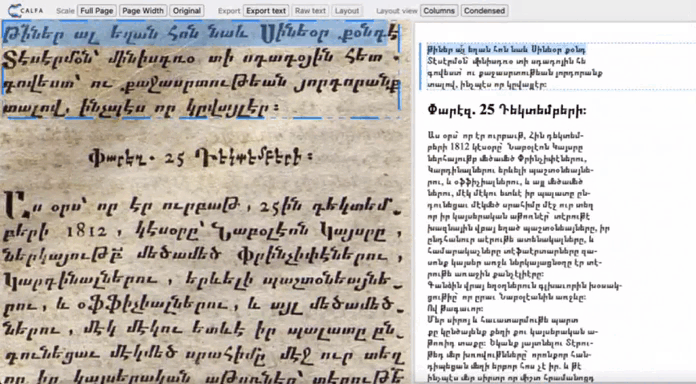
Searchable PDF
From PDF files in input only. The page layout is analyzed : lines and text regions are located, and the recognized text is integrated in the PDF file by over layering on the original page, allowing full-text search.
Available format : PDFOther formats on request
We are also able to deliver the results under other data structures developed specially to fit the technical specifications of your project (databases etc.).
To learn more
Contact us for any question about formatting or how we could help you regarding your project's specifications. Discover Calfa OCR by requesting a free demo with the format you need.