Calfa publie un modèle OCR open source pour l’arménien
La reconnaissance automatique de caractères imprimés (Optical Character Recognition ou OCR) est une étape indispensable pour transformer des documents en donnée exploitable, modifiable et cherchable. On retrouve cette technologie désormais à tous les niveaux, tant au niveau du grand public, des industries que des institutions patrimoniales (bibliothèques numériques).
Pour l'arménien, plusieurs solutions sont disponibles, les plus connues étant :
- Tesseract-OCR, un package open source développé par Google et utilisé comme base pour la plupart des services en ligne. Le modèle arménien couvre un large éventail de polices modernes et permet la transcription de documents propres ;
- Abbyy, un logiciel avec licence permettant de transcrire des documents arméniens standard avec un haut taux de reconnaissance ;
- Calfa OCR, un service en ligne par abonnement prenant en charge toutes les écritures manuscrites et les polices d'impression anciennes, quelle que soit la qualité du document.
En savoir plus sur les performances des OCR pour l’arménien, cliquer ici (en anglais)
| Tesseract | Abbyy | Calfa OCR |
|---|---|---|
| Package | Logiciel | Service |
| Gratuit | Licence | Abonnement |
| Imprimé | Imprimé | Imprimé et manuscrit |
| Polices courantes, documents propres | Documents courants | Polices et documents complexes |
Alors, quelle nouveauté ?
Nous avons entraîné une nouvelle version du modèle arménien de Tesseract, que nous partageons en open source. Ce choix est motivé par notre volonté de soutenir l'effort de numérisation de l'arménien, avec une solution légère et facile à mettre en place, pour les besoins courants.
➢ Accéder au modèle et à Calfa open science
Nous avons renforcé le modèle avec des données plus représentatives de la production imprimée arménienne du XIXe et du XXe siècles. L’accent a notamment été mis sur les documents endommagés et les polices d'écritures anciennes, qui sont habituellement mal reconnues par Tesseract. Le modèle couvre des textes en arménien classique, occidental et oriental. Quelques exemples de reconnaissance :
Exemple 1 : Journal arménien flou (-20% d'erreurs)

| Tesseract default | Tesseract Calfa | |
|---|---|---|
| Character Error Rate (CER) | 28,95 | 8,61 |
| Word Error Rate (WER) | 95,96 | 52,22 |
Exemple 2 : Imprimé arménien en basse qualité (XXe siècle) (-28% d'erreurs)
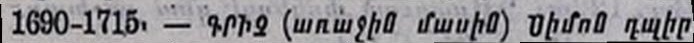
| Tesseract default | Tesseract Calfa | |
|---|---|---|
| Character Error Rate (CER) | 36,64 | 8,11 |
| Word Error Rate (WER) | 101,22 | 44,38 |
Exemple 3 : Scan binarisé d'un livre en arménien (-8% d'erreurs)
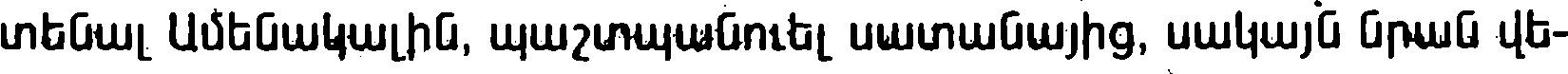
| Tesseract default | Tesseract Calfa | |
|---|---|---|
| Character Error Rate (CER) | 11,75 | 3,99 |
| Word Error Rate (WER) | 50,07 | 21,51 |
Exemple 4 : Police arménienne d'écriture ancienne (-35% d'erreurs)

| Tesseract default | Tesseract Calfa | |
|---|---|---|
| Character Error Rate (CER) | 48,93 | 13,47 |
| Word Error Rate (WER) | 134,90 | 67,63 |
✅ Ce que fait ce modèle :
- Transcription de fonts anciennes ;
- Transcription de documents ou scans abimés ;
- Couverture de l’arménien classique, occidental et oriental.
❌ Ce que ne fait pas ce modèle :
- Analyse de la mise en page : le modèle utilise les capacités par défaut de tesseract pour l’analyse de la mise en page ;
- Post-OCR correction
Pourquoi et comment l’utiliser ?
Ce modèle peut être utilisé directement sur son ordinateur en installant Tesseract-OCR, ou être intégré à un service via l’utilisation de l'API pytesseract. Le modèle est également disponible sur notre outil de traitement ocr.calfa.fr.
La technologie OCR est aujourd’hui de plus en plus accessible, y compris au sein des modèles d’IA génératives. Ce modèle est extrêmement léger (3 Mb), et avec un temps d’inférence inférieur à la seconde pour des pages courantes. C’est une alternative économique, rapide et efficace pour divers projets d’OCR. Pour des modèles plus spécialisés, vous pouvez nous contacter pour une étude personnalisée de votre projet en coûts et faisabilité.
➢ En savoir plus sur notre engagement pour la science ouverte
{kind=link}